*Time sharing: è praticamente il concetto della multiprogrammazione, si cerca di spartire il tempo di utilizzo della CPU tra le task di utenti diversi.
Processo: è un insieme di istruzioni in sequenza che vengono eseguite e dalla memoria utilizzata dallo stesso.
Un programma, sotto richiesta di un utente, può diventare un processo.
Un processo avrà in memoria 3 segmenti: un di stack, uno data e uno di codice.
Un S.O. basato sulla multiprogrammazione deve poter distinguere i processi l'uno dall'altro. I processi hanno una variabile, detta anche pid, che contiene un numero intero ( che parte da 1) che contraddistingue una task dall'altra. Tutti i processi sono raccolti in una tabella dei processi che contiene i nomi dei processi, la CPU utilizzata, la memoria utilizzata.
Questa tabella viene utilizzata da un programma interno del S.O. chiamato scheduler.
Lo scheduler ha il compito di scegliere il processo da eseguire tra la tabella dei processi tramite un algoritmo; esso dovrà avere alcune caratteristiche per eseguire il suo lavoro in maniera ottimale:
- Dovrà essere equo con i processi, senza monopolizzare le risorse ad un unico processo
- Dovrà essere rapido nella scelta del processo da eseguire, indipendentemente dal numero di processi da eseguire
Naturalmente dovrà rispettare anche la gerarchia dei processi: un processo in kernel mode avrà sicuramente più privilegi di un processo in user mode.
Ad ogni cambio di processo avviene anche un cambio di contesto: I dati del processo vengono salvati in memoria insieme ad altri dati come lo stato della CPU, il numero dell'istruzione a cui il processo è arrivato e altri dati.
Per passare da un processo all'altro intercorre un tempo chiamato time slice: questi tempo serve per permettere il passaggio da un contesto all'altro (cioè di cambiare ambiente del processo).
Questo tempo su i sistemi con kernel Linux può essere modificato a piacere, ma può essere dannoso per l'affidabilità di un computer mettere un tempo troppo piccolo, perché il S.O. potrebbe non riuscire a cambiare contesto in tempo, mentre se si mette un tempo troppo elevato ne risentiranno le prestazioni del PC.
Processi:
Un processo su una CPU uniprocessore può essere in quattro stati distinti:
- Running: Il processo è in esecuzione e sta svolgendo le sue istruzioni
- Ready: Il processo può essere eseguito dalla CPU
- Wait o Block: il processo è in attesa, ad esempio di dati ecc...
- Zombie: è un processo che ha finito la sua esecuzione, ma possiede ancora un pid è una variabile da far ritornare al padre, come un intero, un float, una stringa...
Questo tipo di processo si crea quando un padre di un processo genera un processo figlio e non aspetta il ritorno del valore dal figlio.
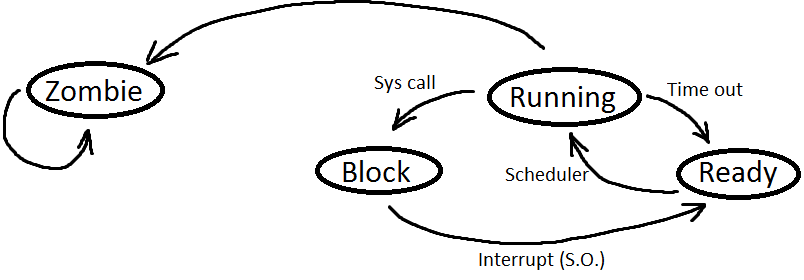
Un job che sta girando sul processore può subire un'interruzione se deve eseguire dei trasferimento dati in input/output facendo una system call andando in wait, oppure ha superato il quanto di tempo ha sua disposizione ( Time out) verrà interrotto, andando nello stato Ready. ( Un quanto è un periodo di tempo che il S.O. dedica ad un singolo processo. Più il quanto sarà grande, più il sistema sarà orientato verso il CPU-bound, cioè sistemi che vanno a scatti ma che ha a disposizione più tempo per sfruttare la CPU; il contrario invece, cioè un quanto più piccolo per processo si avrà un sistema predisposto per verso il I/O- bound [ Input/output], dando però un passaggio un sistema più fluido).
Dopo aver ricevuto i dati che gli servivano il processo andrà nello stato di Ready.
I processi tra di loro possono comunicare (IPC, Inter Process Communication). Naturalmente i processi devono essere predisposti per lo scambio di dati.
I processi che non hanno una fine, tipo l'interrupt per aumentare l'ora dell'orologio, quello della tastiera, del mouse ecc.. su Linux si chiamano demoni (daemons), ed essendo processi anch'essi utilizzeranno memoria.
I processi tra di loro possono avere in comune solo il code segment ma solo se lo permette il S.O.
In generale, non condividono memoria.
*Un processo figlio comunica una sola volta con il padre, quando termina e va ritornare un valore.
Nessun commento:
Posta un commento